Kalev Leetaru, a senior fellow at George Washington University Center for Cyber and Homeland Security, has written for The Signal in previous posts. I recently had the chance to ask him about his latest work, processing and analyzing digitized books stretching back two centuries.
Erin: You recently completed research and analysis on large datasets of digitized books. Could you give us a brief background of the project.
Kalev: One of the biggest questions I hear about the “big data” revolution is the degree to which the datasets we use define the results that we receive. Put another way, if you ask the same question of two different datasets, how closely will your results match? This is a very important question, as the scale and scope of modern datasets are so massive that it is impossible for humans to fully evaluate and understand their content and they are often constructed in ways that makes it difficult to precisely understand their underlying nuances and potential biases. In particular, there has been reluctance from some quarters of the digital humanities world to trust the results of data mining large digitized archives because of lingering questions of whether the results they get are simply by products of the acquisition practices of that particular archive, or whether they are truly universal and genuine findings.
To explore this further, with the assistance of Google, Clemson University, the Internet Archive (IA), HathiTrust, and OCLC, I downloaded the English-language 1800-present digitized book collections of IA, HathiTrust, and Google Books Ngrams collections. I applied an array of data mining algorithms to them to explore what the collections look like in detail, and how similar the results are across the three collections. For each book in each collection, a list of all person names, organization names, millions of topics, and thousands of emotions from “happiness” to “anxiety,” “smugness” and “vanity” to “passivity” and “perception” were calculated, along with disambiguating and converting to mappable coordinates all textual references to location. A full detailed summary of the findings are available online and all of the computed metadata is available for analysis through SQL queries.
Erin: As you mentioned, you were able to compile a list of all people, organizations, and other names, and full-text geocode the data to plot points on a map. How do you think visualizing these collections helps researchers access or understand them, individually or collectively?
Kalev: Historically we’ve only been able to access digitized books through the same exact-match keyword search that we’ve been using for more than half a century. That lets a user find a book mentioning a particular word or passage of interest, but doesn’t let us look at the macro-level patterns that emerge when looking across the world’s books. Previous efforts at identifying patterns at scale have focused largely on the popularity of individual words over time, but that doesn’t get at the deeper questions of how all of those words fit together and the things they tell us about the geographic, thematic, and emotional undertones of the world’s knowledge encoded in our books. For example, being able to create an animated map of every location mentioned in 213 years of books, or all of the locations mentioned in books about the American Civil War or World War I are things that have simply never been possible before. In short, these algorithms allow us to rise above individual words, pages, and books, and look across all of this information in terms of what it tells us about the world.

Erin: Data mining is often cited as valuable for finding patterns and/or exceptions in large corpuses of data. Could you give us an example of your analysis where you’ve found a pattern across these archives of digitized texts?
Kalev: There are quite a few fascinating examples in just the short amount of exploration that I have been able to do with the data thus far, but one particularly striking example is an animated map I made showing all of the locations mentioned by year in books published from 1800 to 2013. While Google itself had previously published four maps back in 2007 showcasing the concept of mapping books, this is the first map to exhaustively visualize the geography of millions of books down to the city and hilltop level globally over two hundred years. What is so fascinating about the animation is that you see exquisitely clearly the emphasis of American books starting off in the early 1800’s on the Eastern seaboard and Western Europe, gradually expanding across America throughout the nineteenth century with the Westward expansion, and reaching into Latin America, Africa, India, and Asia over time. You can even see specific regions and cities light up over time as they became central figures in politics and world events of the day.
Erin: What was the most challenging aspect of the project?
Kalev: There were a few challenges. Obviously the computational demands of the project were quite substantial. It required over 160 processors and 1TB of RAM to analyze the books, a cloud storage fabric capable of storing 3.5 million books with 160 processes reading and writing the same shared file system in parallel, a machine with 32 cores, 200GB of RAM, 10TB of solid state disk, and 1TB of direct-attached solid state scratch disk to consolidate and merge all of the results into the final output. With computing support provided by Google, the entire project took just two weeks from start to finish. I think this demonstrated that with modern cloud environments, even processing 3.5 million books can be achieved very rapidly, instantly leveraging large amounts of highly specialized computing hardware.
In fact, the most challenging part of the project actually revolved around metadata and trying to understand the odd nuances of the collections. For example, the data showed clearly that results using the three collections diverge sharply in the post-1922 copyright era, but that left the key question of what could be driving that difference. This meant really exploring the collections in detail, looking at things like subject tag composition, publishers, authors, and the textual contents of the books looking for clues and patterns to what changed after 1922. None of the three collections publish rich in-depth collection guides that document the precise criteria used by each library and scanning center to determine which books were scanned and which were not scanned, and why, or the reason for certain books having subject tags while others do not.
Publication dates were perhaps the most difficult to deal with of all. IA provides a single publication date for each book, determined by the scanning center as the book is ingested into IA’s holdings and taking into account all known information about the work, while Google similarly has determined a single date for each work. On the other hand, HathiTrust provides multiple dates for each book across a variety of metadata fields, reporting reprints, new editions, translations, serial issuances, and so on, and these often are wildly different from each other and HathiTrust’s own algorithmically-determined publication date. I found this required understanding of MARC XML to interpret, placing more of the burden on the end user of the collection.
Erin: What do you think is the most interesting finding? What surprised you most?
Kalev: I think the single most important and interesting finding was that all three collections yield nearly identical results from 1800 to 1922, but diverge sharply afterwards. The close alignment of the three collections in the public domain era suggests that results derived from analyzing or data mining content in that period should not be influenced by the collection used. On the other hand, it also means that scholarly analysis of books will encounter problems when trying to explore topics in the post-1922 era.
Google Books Ngrams data shows no perceptible change across the copyright boundary, suggesting that its composition does not change markedly in the copyright era. This means that scholars needing only to trace the relative popularity of a particular word or phrase over time will likely find the Google Books Ngrams dataset the easiest to use and allows uninterrupted analysis from 1800 to 2008. Analysis needing to operate on full text or needing greater flexibility in constructing specific filtered sub collections of books should focus on the 1800-1922 period and will get the same results from either IA or HathiTrust collections. In this case, IA collection is likely the best choice for most scholars since it is completely open, does not require any licensing agreements or research and results preapproval, and data can be freely shared with the public, making replication analyses possible. On the other hand, HathiTrust offers an additional special collection of non-public-domain materials that were beyond the scope of my analysis to examine.
Other interesting findings include the markedly different acquisition strategies of IA and HathiTrust collections in the post-1922 era, with IA emphasizing university materials like student newspapers, while HathiTrust has focused on US Government publications like legal and budgetary texts. The extremely low availability of subject tags in the 1800-1922 era (averaging around 55% of books for IA and around 65% for HathiTrust) was also a surprise, making it very difficult to accurately use subject tags to search and interact with the public domain era of the collections.

Erin: What do you think the role of traditional libraries, museums and archives should be when dealing with data mining projects?
Kalev: One of the things I have learned in my nearly 20 years of mass-scale data mining is that the role of libraries in supporting this kind of mass-scale research is really shifting. When libraries have put forward technical services to make their content more accessible to analysis, it has often focused on small-scale projects, such as APIs that make a single book page at a time available. One of the things that makes IA, HathiTrust, and Google Books Ngrams collections so unique is that they were really designed to facilitate the kind of mass data mining that people like me do, making it trivial to obtain instant bulk downloads of their entire collection for data mining. I could never have done this project if these three archives hadn’t made it possible to mass download their data.
That to me is one role that libraries, museums, and archives can play in supporting data mining projects – providing a clear entrance point for scholars who are interested in mining their collections. While not every library has the resources to make these kinds of interfaces possible, one step every library can do is to provide a named point of contact as an entrance point for researchers interested in using their collections for large-scale analysis. That facilitates a dialog where institutions have visibility into what kinds of questions researchers are interested in exploring using their collections, allowing them to offer guidance and suggestions for working with the material, establishing access workflows that minimize the load and risk to their websites and technical infrastructure, and address up front any concerns or complications that the analysis might pose in terms of licensing or other agreements. This to me is the ideal and necessary role for institutions moving forward, since as bulk downloading tools become easier to use, more and more scholars are simply bulk downloading vast archives without engaging with the host institutions.
Erin: You’ve talked about the value of mapping over time news archives and now digitized books. Do you think these kinds of projects could make a case for preservation of data?
Kalev: I think that’s actually one of the most exciting aspects of this research. Three years ago when I gave the opening keynote address at the 2012 IIPC General Assembly, I had many attendees come up to me afterwards and lament that as budgets have continued to shrink, many have been faced with increasing questions about the role and utility of libraries and their collections in the modern era. A common refrain I heard was a growing notion that libraries were outdated and why should they be given funding to preserve all of this material that we have no idea if anyone will care about down the road. It is difficult today to get funding to just collect and preserve the world, but at the same time funding is exploding for research that tries to make sense of the vast archives of data around us. This is where I think libraries can play such a huge role in making their collections available for this kind of research. Libraries have been collecting and preserving the world’s knowledge for thousands of years, but historically that focus has been on discrete artifacts like books, treating them more as museum artifacts than containers of knowledge.
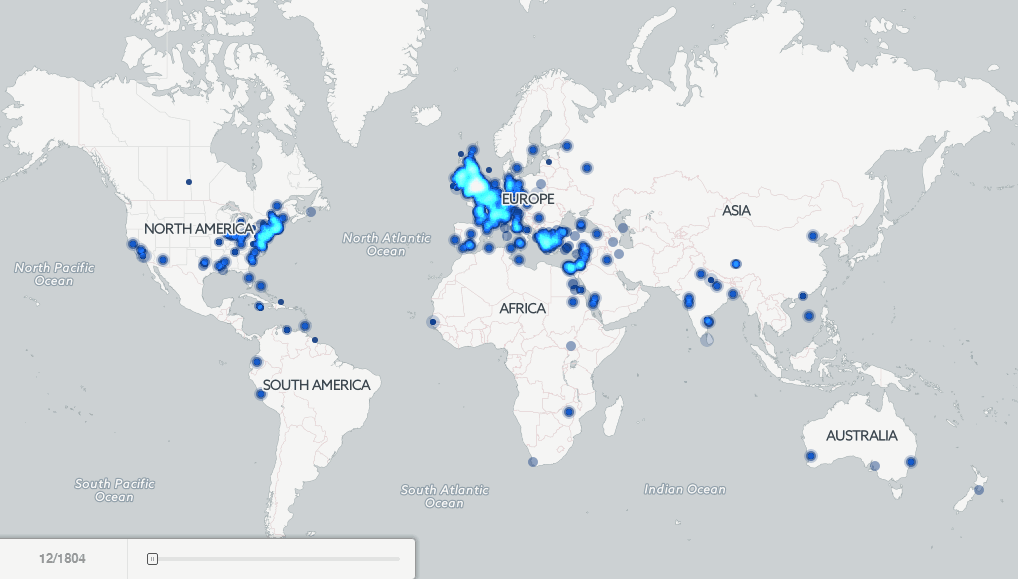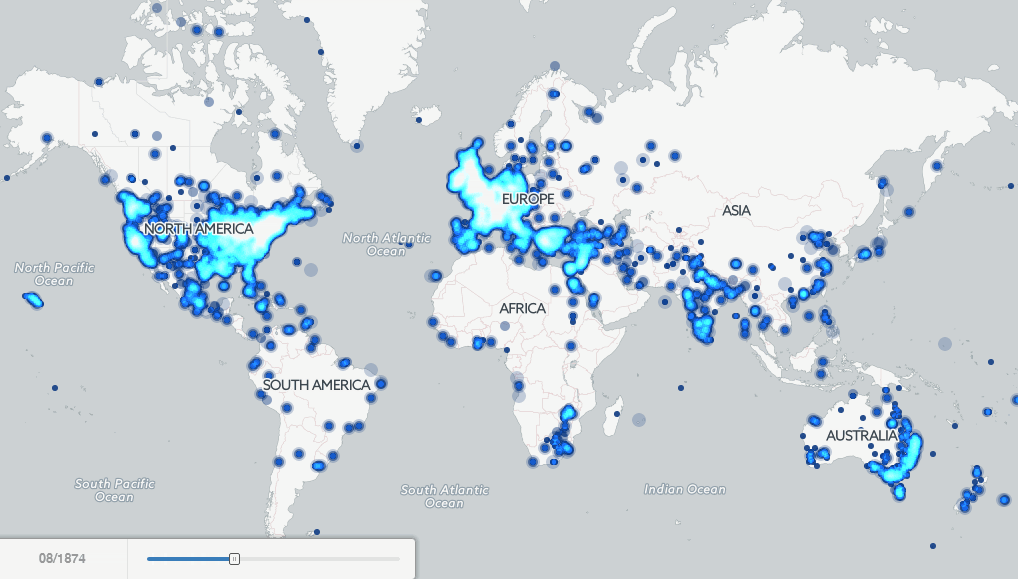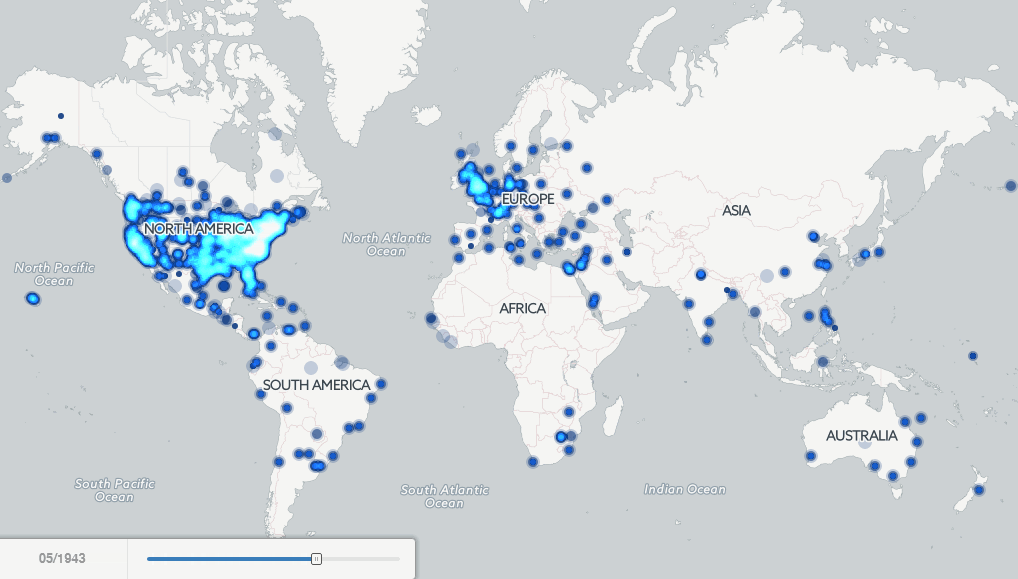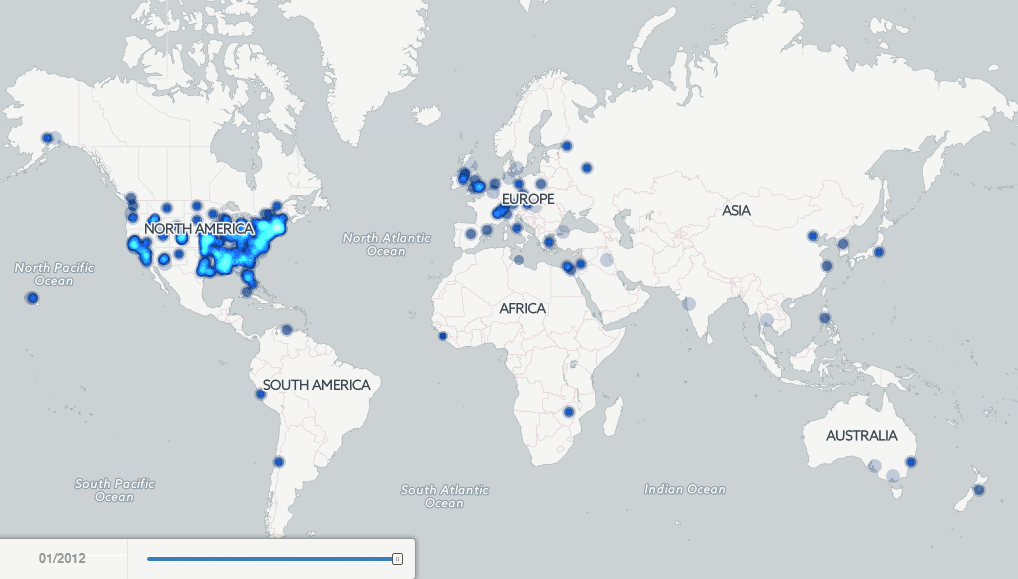
Twenty years ago I could never have taken 3.5 million books, extracted and disambiguated every textual reference to a location anywhere in all those books, and made an animated map showing the geographic evolution of the world’s books. It’s only because these digital library efforts have aggregated these massive archives of information into a single place and made it available for bulk data mining that I was able to do this project. Now imagine if libraries make more and more of their holdings available for this kind of at-scale exploration by scholars? In fact, I’ve been collaborating closely with the Internet Archive over the last two years to explore what this might look like, prototyping with them a “virtual reading room” that we have used to map television, explore political communication in television, and mine the open web.
Instead of focusing on libraries as museums of artifacts, I think if we change the conversation to what those vast archives can enable, thinking of libraries as “conveners of information and innovation,” that really reshapes the narrative around the role that libraries play in society and really makes the argument for why they should be collecting and preserving all of this material. And as that material becomes at greater and greater risk, the ability of libraries to preserve and protect it for future generations becomes all part of the story around the evolving role of libraries in today’s world.