This is a guest post by Rachel Trent, Digital Collections and Automation Coordinator in the Geography and Map Division. Every time you look at an online image of a historical map, what you’re viewing is really just a spreadsheet of numbers. Or more likely, three spreadsheets, one each for red, green, and blue (the technical way to …
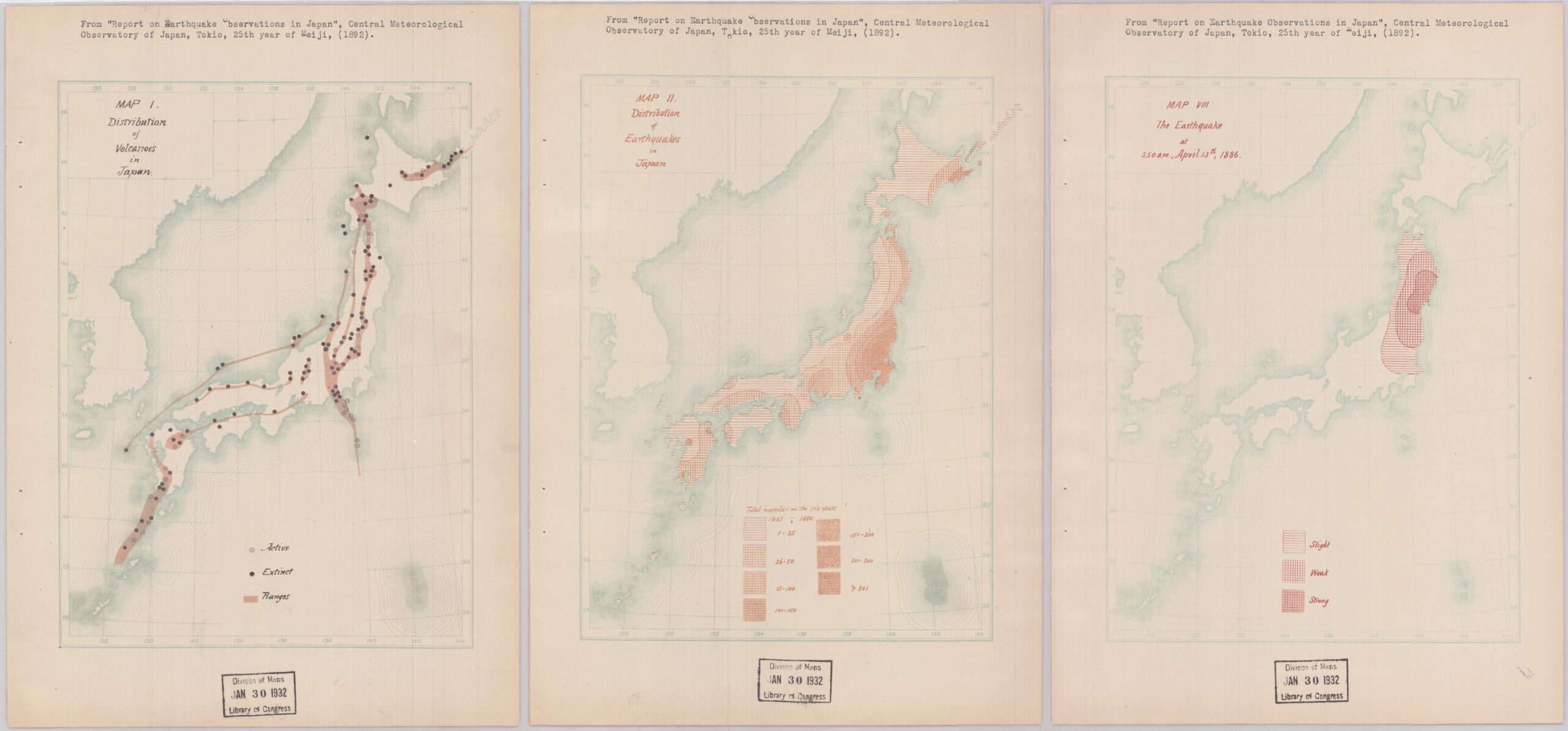
Did you know that worldwide, roughly 55 earthquakes are recorded per day? Of course, the vast majority of these seismic events are minor, making it all the more impressive that we are able to detect them. The technology used to gather data on earthquakes and seismic movements has vastly improved over time, and with it …
On October 27, 2022, the Library of Congress held an event for members of the Philip Lee Phillips Society, the Washington Map Society, and the Friends of the Library of Congress. The event was named “Explore the Depths of the Geography and Map Division.” Unusual maps and atlases from the collections of the Geography …
On the Geography and Map Division home page, we keep a list of maps newly placed online. As has become tradition (see previous Year in Review posts), to celebrate the end of a year and to ring in the new, I take a look back at the digitized maps that are now available online from …